Abstract
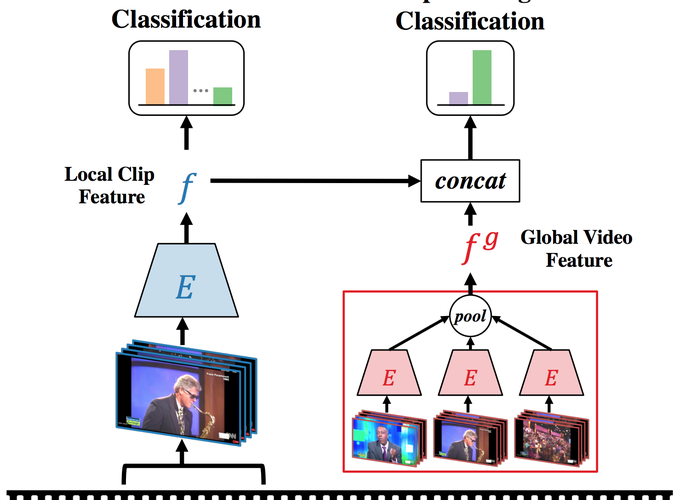
Understanding videos is challenging in computer vision. In particular, the large memory footprint of an untrimmed video makes most tasks infeasible to train endto-end without dropping part of the input data. To cope with the memory limitation of commodity GPUs, current video localization models encode videos in an offline fashion. Even though these encoders are learned, they are typically trained for action classification tasks at the frame- or clip-level. Since it is difficult to finetune these encoders for other video tasks, they might be sub-optimal for temporal localization tasks. In this work, we propose a novel, supervised pretraining paradigm for clip-level video representation that does not only train to classify activities, but also considers background clips and global video information to gain temporal sensitivity. Extensive experiments show that features extracted by clip-level encoders trained with our novel pretraining task are more discriminative for several temporal localization tasks. Specifically, we show that using our newly trained features with state-of-the-art methods significantly improves performance on three tasks: Temporal Action Localization (+1.72% in average mAP on ActivityNet and +4.4% in mAP@0.5 on THUMOS14), Action Proposal Generation (+1.94% in AUC on ActivityNet), and Dense Video Captioning (+0.31% in average METEOR on ActivityNet Captions). We believe video feature encoding is an important building block for many video algorithms, and extracting meaningful features should be of paramount importance in the effort to build more accurate models.