Abstract
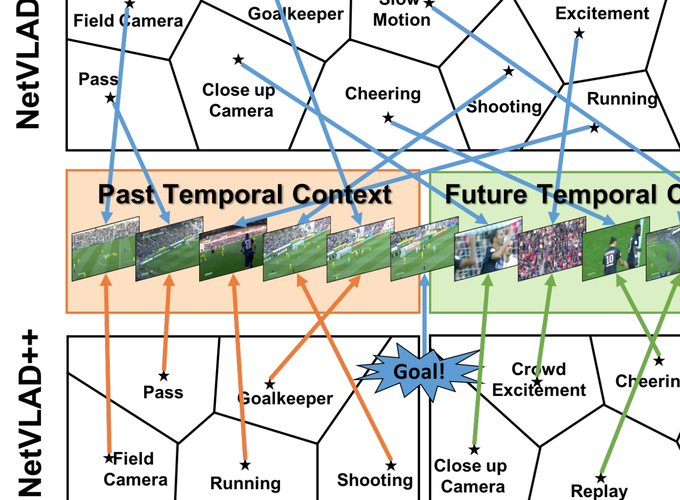
Toward the goal of automatic production for sports broadcasts, a paramount task consists in understanding the high-level semantic information of the game in play. For instance, recognizing and localizing the main actions of the game would allow producers to adapt and automatize the broadcast production, focusing on the important details of the game and maximizing the spectator engagement. In this paper, we focus our analysis on action spotting in soccer broadcast, which consists in temporally localizing the main actions in a soccer game. To that end, we propose a novel feature pooling method based on NetVLAD, dubbed NetVLAD++, that embeds temporally-aware knowledge. Different from previous pooling methods that consider the temporal context as a single set to pool from, we split the context before and after an action occurs. We argue that considering the contextual information around the action spot as a single entity leads to a sub-optimal learning for the pooling module. With NetVLAD++, we disentangle the context from the past and future frames and learn specific vocabularies of semantics for each subsets, avoiding to blend and blur such vocabulary in time. Injecting such prior knowledge creates more informative pooling modules and more discriminative pooled features, leading into a better understanding of the actions. We train and evaluate our methodology on the recent large-scale dataset SoccerNet-v2, reaching 53.4% Average-mAP for action spotting, a +12.7% improvement w.r.t the current state-of-the-art.
Silvio Giancola
Research Scientist
Silvio Giancola is a Research Scientist at King Abdullah University of Science and Technology (KAUST), working under the supervision of Prof. Bernard Ghanem in the Image and Video Understanding Laboratory (IVUL), part of the Visual Computing Center (VCC).